OOSE 2014 Team 16
Customizable Brain Analysis Database
Iteration 1
Iteration 2
Iteration 3
Iteration 4
Iteration 5
Iteration 6
Group Members
- Rachel Coston
- Ezgi Ergun
- Guannan Ren
- Kai Zhang
Iteration Plan
- Iteration 3
In this iteration have set up Hibernate with Eclipse based on a Derby Database on our local machines. At this time we are not sharing a database to allow us to experiment with the database without breaking everyone else's database.
We have written JUnit tests for our core functionality, our model package. These tests all fail as expected. We have chosen to code defensively due to the sensitive nature of our data and the need for it to be accurately represented in the database. The JUnit tests reflect this decision. Our tests will attempt to pass bad data, null data, or the class being tested will have bad data. The exceptions thrown will be handled in the UI.
In this iteration we had planned to implement xml parsing. In our further research into JIST and MIPAV we discovered that this could be done before passing the data to our Java code. Our extractFields method of our XMLImageData will then parse the output file given by MIPAV as a hashtable.
We had planned to implement data correlation in this iteration, but setting up the database took longer than expected. Due to compatibility issues we ended up having to use Hibernate 3. We will implement this in iteration 4
We created a basic JIST module to understand how our module will work with the existing software.
- Iteration 4
In this iteration we created a basic JIST module that provides the main user interface. The module defines the user's view of the functionality and allows the user to send inputs, such as subject information (age, gender, demographics). We aim to have our module chain with JIST’s other modules for image processing and storage. This involves allowing database administrators to upload data folders, automatically organizing and correlating data and image processing.
We have created a swing GUI that will be the main interface for the database administrator. The GUI is not completly integrated with the Hibernate database. Currently we are able to add users from the database administrator's GUI
The current JIST Application can either be run locally, as we are doing for development, or in a lab setting remotely. For this reason we do not need to implement a client/server interface for JIST. Our addition is the database, which should be run on its own Database Server. We selected Derby as our database since it can also funcion as a database server. In order to create a centralized database we would need to deploy Derby to a dedicated host. Then, on the host, change the hostname in the derby.drda.host property so that is not localhost and therefore accessable from other machines. In order to connect this with our model code we need to change the database connection URL in the hibernate.cfg.xml to the host we chose for Derby. Unfortunalty we do not have access to a machine that could serve as this remote host. So we will continue to use local databases that we periodically sync. On our computers we will run Derby as a database server on localhost. We have included the diagrams for the client/server/server/database interface.
We are still working on integrating Hibernate with JIST. We have implemented database queries using the Hibernate Query Language. Once we connect the user inputs with the database manager, the manager will allow authorized users to dynamically retrieve data used for image processing. We are still working on providing access control (username/password) for the database user.
- Iteration 5
Alpha Release
In this iteration we implemented access controls to the administration tool allowing only database administrators to log-in.
In this release the database administrator is able to add image path, process type creation, default process type selections to the database.
We worked on the customizable report generation for the database administrator. However, this part proved to be very difficult, and we still have bugs in this code.
Automatic image processing is not yet completed, but we completed the GUI for this. The database administrator can also register new users and database administrators.
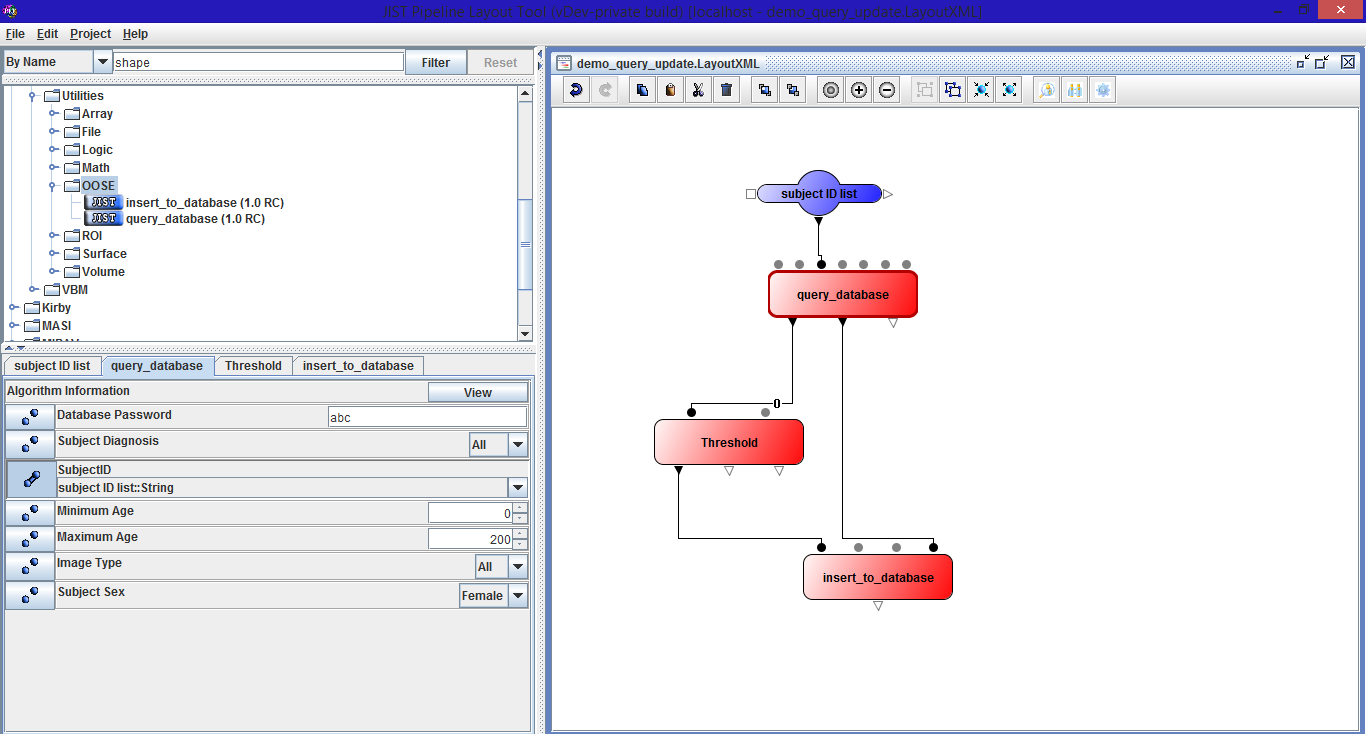
Users can access the Hibernate database through the JIST interface. We added a field called "Database Password" so that only authorized users can access the database. If the password is incorrect the database will not be queired. The users can enter queries in JIST and will get a list of image locations that meet their criteria
- Iteration 6
Beta Release
Program Overview
We created a database system to allow the users of JIST to centrally store, update, and retrieve data. In order to change any data in the database, the user must use the database administrator's user interface. This interface requires the administrator to enter a password before allowing the user to view the interface. The database administrator can input images and test results. When test results are entered they are automatically corrolated to any images taken on the same day with the subject id. The administrator can define the defalut image processes, create new users, and view reports of past imports.
We created a JIST module to query the database. The user must enter a valid password in order to query the database. The database can be searched by: subject diagnosis, subject ID, age, image type, subject sex or any combination of the 5 fields. This module can be connected in a JIST pipeline so that the current functionality can be leveraged.
We created a JIST modlue to save processed images back to the database. The user must enter a valid database administrator credentials. This is typically placed at the end of a pipeline.
JIST Layout Example: Query by Subject ID, perform a simple image processing procedure, and save the processed images back to the database
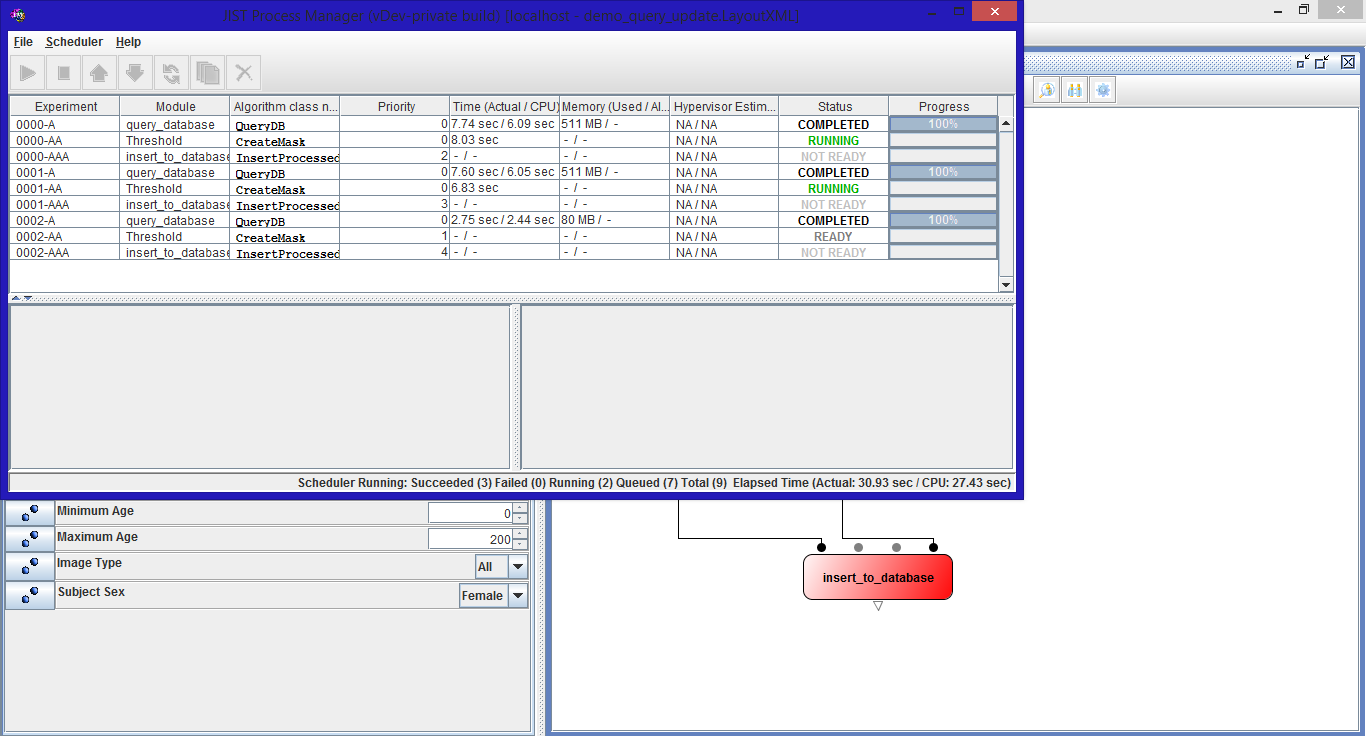
- Iteration 7
Release
Given more time we would provide a JIST module that allowed users to query the database using test results and vice versa. We would also like to provide a module to convert between collections of volumnes and volumes to allow greater versatility. In order to improve the database schema, we would like to meet the people that want to use this program so we can better meet their needs.
JavaDoc
Please click here for the JavaDoc Documentation
Databases
Please click here for the database tables
Code
Please click here and here to download the source code